Claude Sonnet 4.5 Benchmark Results
Comprehensive evaluation results across key AI capability domains reported by Anthropic
Claude Intelligence Comparison
Model Generations
Intelligence comparison across Claude model generations using Artificial Analysis Intelligence Index.
Coding Performance - 82.0%
SWE-bench Verified
Best coding model in the world. Data from SWE-bench Verified with parallel test-time compute.
Intelligence Benchmark - 63
Reasoning & Problem-Solving
Artificial Analysis Intelligence Index composite score measuring reasoning and problem-solving.
Math Competition - 88.0%
AIME 2025
Data from AIME 2025: Advanced mathematics competition performance from Artificial Analysis.
Claude Models Comparison
Performance analysis comparing Claude Sonnet 4.5 with other Claude models using real data from Artificial Analysis.
Claude Intelligence: Model Generation Comparison
Intelligence comparison across Claude model generations using the Artificial Analysis Intelligence Index.
Intelligence Index aggregates results from several reasoning tasks, normalizes them to a standard scale, and reports one composite for easy comparison.
In this dataset, Sonnet 4.5 leads the Claude line at 62.7, ahead of 4.1 Opus at 59.3 and 4 Sonnet at 56.5, which points to better consistency on multi-step problems and cross-domain questions. Treat the score as directional context rather than an absolute claim of task-specific supremacy.
- Claude Sonnet 4.5: 62.7 on the Intelligence Index
- Margin vs Claude 4.1 Opus: +3.4 points (62.7 vs 59.3)
- Lift vs Claude 4 Sonnet: +6.2 points (56.5 to 62.7)
- Lift vs Claude 4 Opus: +8.5 points (54.2 to 62.7)
- Lift vs Claude 3.7 Sonnet: +12.8 points (49.9 to 62.7)
Evolution notes: Claude 3.5 set a balanced baseline in reasoning and coding. Claude 4 delivered major gains in complex, multi-step tasks. Sonnet 4.5 is Anthropic's latest step up in composite intelligence.
Source: Artificial Analysis Intelligence Index Leaderboard
Coding Performance
Coding Performance spotlights how Claude Sonnet 4.5 handles real engineering work. We use SWE-bench Verified because it measures fixes to authentic GitHub issues with full test suites, which is a closer proxy to day-to-day software development than synthetic coding quizzes. The focus here is simple: did the model ship a passing fix under realistic conditions, and how often?
SWE-bench Verified evaluates code edits on real repositories with comprehensive tests. A task counts as solved only when the model's patch passes the repo's tests. Results shown here use parallel test-time compute, which means the system runs multiple concurrent attempts and selects the variant that passes.
This setting reflects how production teams often run a beam or batch search to raise reliability.
- 82.0% on SWE-bench Verified for Claude Sonnet 4.5 with parallel test-time compute.
- Best coding score in this dataset on the most widely cited real-repo benchmark.
- Test design: real GitHub issues, comprehensive test coverage, and passes are counted only when tests succeed.
- Run setting: parallel test-time compute improves pass rates by selecting the strongest patch among concurrent attempts.
Source: Anthropic official announcement, September 29, 2025.
Claude vs Leading AI Models
Performance comparisons between Claude Sonnet 4.5 and the world's most advanced AI models.
AI vs Human: The Physics Intuition Test
Testing how well AI models predict simple real-world physics scenarios against a human baseline.
How the Physics Intuition Benchmark Works
The Visual Physics Comprehension Test (VPCT) evaluates whether AI models can reason about very simple physics scenarios.
Example Problem
Below is one of the 100 test problems. A ball starts at the top and rolls down the ramps.
Prompt given to both humans and AI models:
"Can you predict which of the three buckets the ball will fall into?"
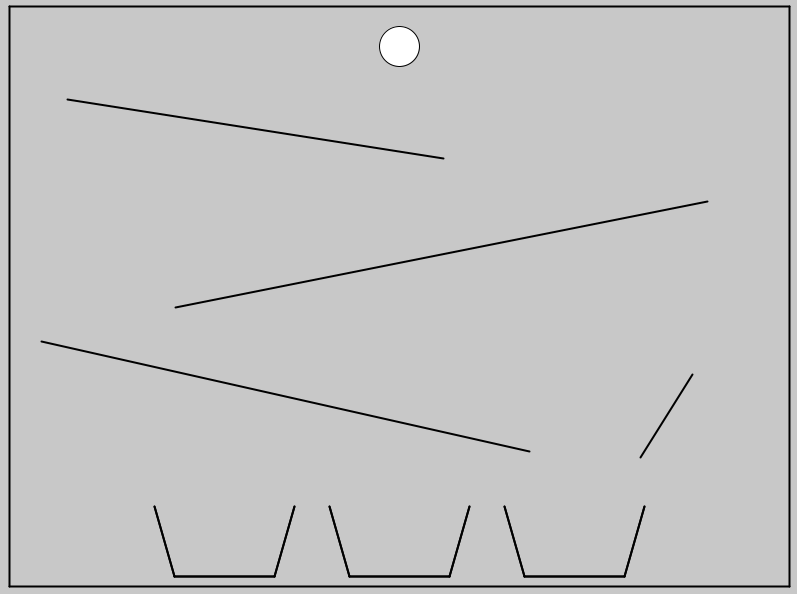
The Benchmark Setup
- Dataset: The benchmark includes 100 unique problems like the one above, each with different ramp configurations.
- Solutions: The official answers are available here: VPCT dataset on HuggingFace.
- Human Baseline: Humans find these puzzles trivial. In testing, volunteers scored 100% on all problems.
- AI Performance: Vision-language models (GPT, Claude, Gemini, etc.) are evaluated on the same 100 problems. Older models performed near random guessing (~33% accuracy), but newer reasoning-focused models have shown significant improvements.
- Claude 4.5 Result: On this benchmark, Claude 4.5 scored 39.8%. This is slightly above random guessing, but far below human performance. The result shows signs of emerging physical intuition, yet it still struggles with problems that are effortless for humans.
Why It Matters
VPCT measures physical intuition, core abilities for robotics, planning, and real-world interaction. Progress here is a crucial indicator of whether models are developing grounded intelligence, not just language fluency.
Source: Visual Physics Comprehension Test by Chase Brower
Intelligence Benchmark (Claude vs Leading AI Models)
Composite score measuring reasoning, problem-solving, and knowledge across multiple domains from Artificial Analysis
About the test, the Artificial Analysis Intelligence Index is a normalized composite that aggregates results from several reasoning and knowledge tasks under a consistent setup. Scores run from 0 to 100, which lets you track gaps between vendors and progress across model generations.
- Claude Sonnet 4.5 score, 63 on the composite intelligence index
- Margin vs Claude 4.1 Opus, +2 points (61 to 63), confirming a clear family level lift
- Gap to the leader, 8 points vs GPT 5 Pro High at 71, 6 points vs GPT 5 High at 69
- Top models in the chart, 71 GPT 5 Pro High, 69 GPT 5 High, 68 Grok 4, 65 Grok 4 Fast, 65 Gemini 2.5 Pro, 64 DeepSeek R1 Terminus, 64 Qwen3 235B, 63 Claude Sonnet 4.5
- Position, upper mid pack among leading models, and best within the Claude family in this dataset
Source: Artificial Analysis Intelligence Index Leaderboard
Math Competition
Data from AIME 2025: Advanced mathematics competition performance from Artificial Analysis
AIME problems are short, multi-step questions with integer answers. Scoring is strict, no partial credit, which makes it a clean way to compare models on precise reasoning. Setups vary by evaluator, including whether tool use or extended thinking is enabled.
The score shown here follows the Artificial Analysis configuration for consistency across models.
- Claude Sonnet 4.5: 88% accuracy at AIME 2025.
- Beats Claude 4.1 Opus by +7.7 points (80.3 to 88.0).
- Near the upper tier but behind the leaders, GPT 5 Pro High 98.7, GPT 5 High 94.3, Gemini 2.5 Flash High 93.4, Grok 4 92.7.
- Within striking distance of DeepSeek R1 Terminus 89.7 and Grok 4 Easy 89.7, and a hair above Gemini 2.5 Pro 87.7.
Source: Artificial Analysis AIME 2025 results.
AI Model Speed Comparison
Compare real-time token generation speeds between any two AI models. Watch as they generate 200 tokens (≈150 words) side by side.
First Model
Second Model
Real User Feedback on Claude Sonnet 4.5
Claude Sonnet 4.5 can autonomously create a chat app akin to Slack or Teams by producing 11,000 lines of code over 30 hours. pic.twitter.com/FRN7jNGYGQ
— prinz (@deredleritt3r) September 29, 2025
This user mentions one of the strongest indicators of improvement: Claude can now function as a solo builder for large codebases under the right prompts and tools.
My final review for Claude Sonnet 4.5
— 0.005 Seconds (3/694) (@seconds_0) October 1, 2025
- Its better than Sonnet 4 by a significant margin
- Its very fast
- It is NOT better than Codex by a significant margin
- Anthropic's refusal to cost down makes it unusable outside of a Max Plan; simply doesn't make sense financially
This user echoes a common sentiment among power users: Claude 4.5 Sonnet is technically impressive but financially inaccessible. In short, it's a great model with gated deployment.
Claude Sonnet 4.5 vs 4.0 (measured on coding tasks):
— Augment Code (@augmentcode) October 1, 2025
App from scratch
→ 4.5: ~20min, functional build.
→ 4.0: 40+min, lower quality.
Simple code change
→ 4.5: 3 tool calls, correct edit.
→ 4.0: longer chain, same result.
Complex refactor
→ 4.5: faster + tests passed.
→… pic.twitter.com/VT4TMKHqXY
This comparison offers a clear, quantified look at real-world coding efficiency, and Claude Sonnet 4.5 shows significant gains across the board.
Most notably, it delivers faster builds and cleaner execution paths, especially in complex refactoring, which is often a weak spot for LLMs.
The key insight here is reduced tool churn: fewer calls, less backtracking, and more reliable test-passing code.